
What is Morphological Analysis?

Studying the internal structure of words is known as morphological analysis. It describes the methods and systems used in Natural Language Processing (NLP) to analyze texts at the word level and determine the structure of individual words. In order to extract information that will be helpful for further processing steps, this technique entails breaking down words. Another name for the discovery of word structure is morphological parsing. The process of decomposing words into their most basic, meaningful elements, known as morphemes, is known as morphological analysis NLP.
Generally speaking, words are regarded as the fundamental units of texts in natural languages. The complexity of many words is recognized via morphological analysis. Morphemes, the smallest units of meaning or information, make up words. These elements are sometimes referred to as segments or morphs.
Processes of Morphology
Human languages blend morphs and morphemes into word formations using a variety of mechanisms. Concatenation is the basic procedure, in which morphs are joined one after the other. For example, in “disagreement-s,” “agree” is a free lexical morpheme, whereas the other morphemes are bound grammatical morphemes. Morphophonemic modifications, on the other hand, are phonological and orthographic alterations that result from the interaction of morphs in more complicated situations. Phonology describes the restrictions on word construction caused by pronunciation. Morphophonology, sometimes known as morphonology, is the study of how morphology and phonology interact. This includes the phonology of morpheme boundaries as well as phonological processes related to affixation or other morphological activities.
The two primary categories of morphological processes are derivation and inflection.
Morphology in Inflectional Form:
Using affixes to convey grammatical distinctions like tense, aspect, number, person, gender, and case, a root form is systematically modified in this way. Different variants of the same word are related by their inflection. Usually, it doesn’t drastically change the meaning of the term or change its class. It is common to classify all of a word’s inflectional forms as expressions of a single lexeme. Words of a given class will usually exhibit all conceivable inflections since inflectional morphology is normally near to fully productive. The inflectional morphology of English is somewhat simpler than that of languages such as Finnish.
Morphological Derivation:
By adding derivational affixes, this procedure creates new words from roots or stems. It frequently causes a more drastic change in meaning or can alter the word’s grammatical category, but it is less systematic than inflection. The classes of words to which an affix belongs are less obvious, and derivational morphology is less fruitful than inflectional morphology. There are no clear restrictions on the quantity of derivational affixes that can be applied in a recursive manner, unlike inflection. In contrast to English, which uses syntactic methods, certain languages, such as Inuit, use substantial derivational morphology.
Essential Ideas for Morphological Analysis
- Morphemes: A language’s smallest meaningful units. They may be affixes or stems. Morphemes are little, meaningful components that make up words:
Played = play-ed
Cats = cat-s
Inhospitable means un-friendly
Morphemes come in two varieties:
I Stems: buddy, play, and cat
- Stems: A word’s root form.
- Affixes: Usually affixed to a stem, morphemes that must appear in conjunction with other morphemes. Types consist of:
- Prefixes: These appear before the stem (un- in uncommonly, for example). restricted to English’s derivational morphology.
- Follow the stem when using suffixes, such as -ly for abnormally and -s for dogs.
- As demonstrated by Arabic roots paired with infixes (e.g., k-t-b joined with infixes to generate kataba, kotob), infixes occur inside the stem. Sing, sang, and sung are examples of irregular verbs in English that exhibit remnants of infixation, but modern English does not benefit from this process.
- The circumfixes encircle a stem.
- A lemma, often known as a lexicon, is an abstract entity that serves as the umbrella term for a group of morphological variations. For instance, the set {delivers, deliver, delivering, delivered} is named by DELIVER.
- Lemmatization: Linking morphological variants to their lemma is the fundamental job of lexical analysis. This entails figuring out that, despite their apparent differences, two words share the same origin. Complete morphological parsing may be required.
- Morphosyntactic Properties/Information: Details regarding the grammatical characteristics of word forms, including gender, mood, tense, case, person, and number. Lemmas must be provided with morphosyntactic information in order to be used in lexical analysis. Pairs of features and values can be used to represent this data.
The study of the relationships and interactions between morphology and phonology is known as morphophonology. It takes into consideration the stem and affix variation that can happen in complex words, frequently as a result of affixation-related phonological processes. This may entail textual spelling variations. The English plural prefix -s, for instance, can be pronounced differently (/z/, /ɪz/, /s/). Basic forms must be mapped to orthographic variants by systems, frequently using rule-governed mappings. Combining inflected syntactic words in an utterance might result in further phonological and orthographic alterations.
- Allomorphs: A morpheme’s alternate forms. For example, the plural morpheme can have allomorphs like as -s, -es, and -en.
- Morphotactic: Describes the arrangement of morphemes within a word as well as the combination of stems and affixes.
Morphological Typology
Languages from throughout the world are categorized using morphological typology, which groups them based on shared morphological patterns. Languages are arranged in this field according to the way they combine morphemes to generate words. It describes the morphological phenomena that are common in those languages. The history of linguistics has seen the proposal of numerous classifications based on a variety of factors.
A prevalent framework for morphological typology is predicated on the quantitative relationships among words, their morphemes, and their characteristics. Included in this classification are:
Analytical or isolating languages:
These have few or no words that contain several morphemes. To convey meaning, they utilize elements such as word order and auxiliary words, rather than relying mainly on inflection. Vietnamese, Mandarin Chinese, and Cantonese are a few examples.
Synthetic Languages:
These are non-analytic languages. Additionally, they are divided into fusional and agglutinative languages.
- Agglutinative Languages: Words in these languages frequently split into smaller, distinct morphemes due to the high segmentability of morphemes. Words are often made up of several morphemes. Korean, Japanese, and Turkish are a few examples. There are potentially tens of thousands of morphological variations for a single word in Korean due to its agglutinative and highly prolific morphology.
- Fusional or Inflectional Languages: The distinctions between morphemes in fusional or inflectional languages are less distinct than in agglutinative languages. Component morphemes are able to convey many grammatical meanings. A considerable portion of Latin is regarded as an inflectional language. Word morphology in highly inflectional languages frequently encodes important information, such as gender (e.g., masculine, feminine) or case (e.g., nominative, accusative, genitive).
Polysynthetic Languages:
Languages that are polysynthetic languages are a severe form of agglutinative languages. To create complex words that can stand alone as a whole phrase, multiple morphemes are combined. Siberian Yupik, Chukchi, and Inuktitut are a few examples.
Considering whether a language is concatenative or nonlinear is another method of morphological classification:
- The Languages that link morphs and morphemes sequentially are known as concatenative languages.
- Nonlinear Languages: In nonlinear languages, structural elements can combine nonsequentially, for example, by altering a word’s consonantal or vocalic templates or by applying tonal morphemes.
Most languages have remnants of several categories, though some may have inclinations towards just one.
Natural language processing (NLP) benefits from an understanding of linguistic typology since morphological and other language divergences affect tasks like machine translation. Due to the sparse data problem and a high number of possible out-of-vocabulary words, typical word-based techniques to tasks like Part-of-Speech (POS) tagging may not perform well for languages with complicated morphological structures, such as agglutinative languages. In morphologically rich languages, this calls for more complex analysis, like morpheme-based tagging or the usage of POS tagsets, which are collections of morphological tags, to capture aspects like case and gender. The process of connecting morphological variants to their lemma and related information is known as morphological analysis, or figuring out a word’s underlying structure. This is crucial for lexical analysis.
Linguistic Approaches to Word Structure
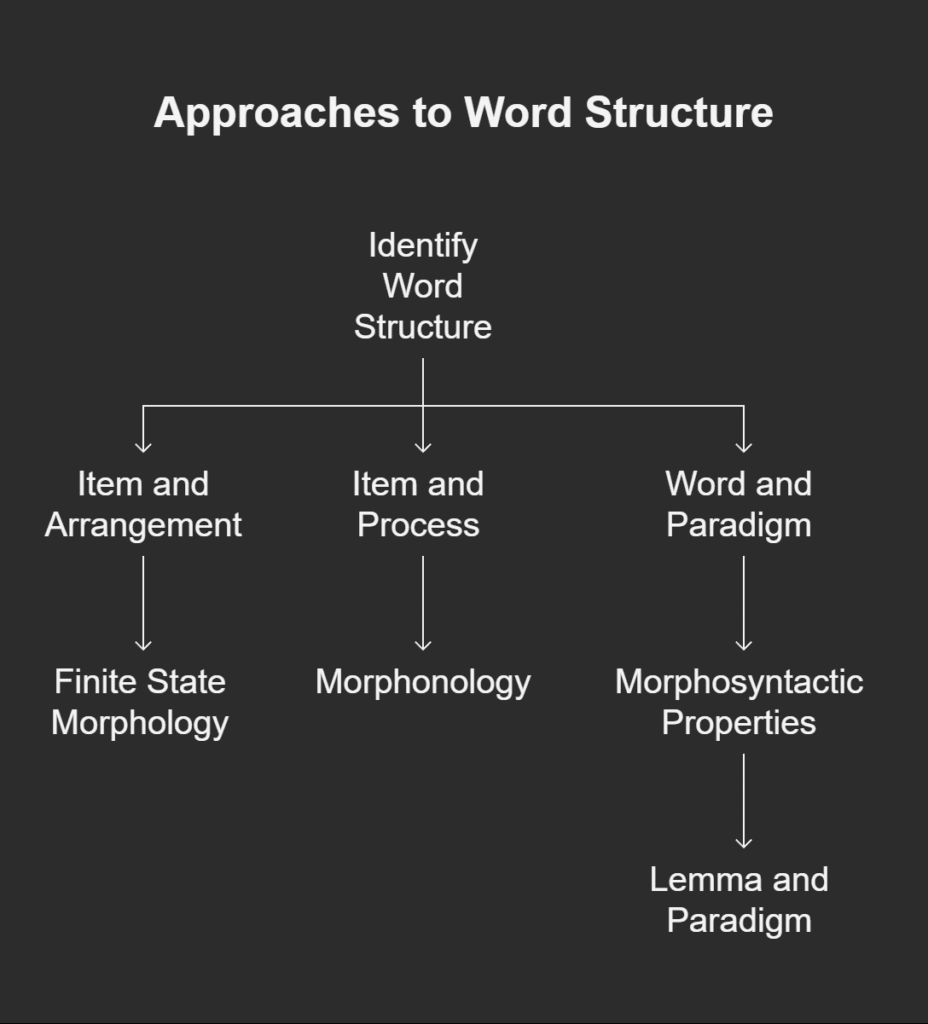
Three primary approaches to word structure are recognized by morphologists as the foundation of computer models:
Item and Arrangement (I&A): This perspective considers analysis to be the computation of information from the stem morpheme and affix morpheme of a word. For words that are easily separated into stem and contiguous affixes, this works well. This perspective is frequently incorporated into finite state morphology.
You can Also Read about Types Of Lexicon: A Complete Guide To Word Resources
Item and Process (I&P): Focusses on morphonology and takes into consideration stem and affix variation brought on by phonological processes.
Word and Paradigm (W&P): Connects a morphological variation to a set of morphosyntactic properties by associating a lemma with a paradigm (a table). The paradigm’s cell definition provides meaning, not always the total of the meanings of the morphemes. This method provides an alternate method of capturing word structure that is not dependent on contiguity (affixes are contiguous) or isomorphism (one feature = one morpheme). It seems to provide a more accurate explanation of “difficult” morphology and has been embraced by numerous theories.
Computational Techniques and Challenges
Finite State Models (FSM/FSTs)
Because of their invertibility (ability to be utilised for both analysis/parsing and generation) and computational efficiency, finite state approaches have long been employed for morphological analysis. The mapping between stems/affixes and their morphosyntactic characteristics can be handled gracefully by FSTs. Morphotactics are encoded by them. The linguistic foundation of FSM is an I&A model.
Handling “Difficult” Morphology
The I&A (isomorphism and contiguity) assumptions are not always strictly followed by many languages.
Isomorphism Issues
A single morpheme exponent and a group of morphosyntactic features rarely map one to one in languages. Languages that are agglutinative can nonetheless exhibit non-isomorphic behaviour. FSM can deal with this by gathering features into symbol sets or by employing empty transitions.
Issues with Contiguity
The exponent isn’t usually a series of consecutive symbols. Semitic languages like Arabic and Hebrew are examples of infixation and root-and-template (or non-concatenative) morphology. In root-and-template systems, the exponent (usually vowels or patterns) interrupts the root (usually consonants). In order to deal with this, FSM reframes it as a linear problem. W&P techniques are said to provide more natural explanations of noncontiguous morphology by utilising ideas like heredity and defaults (as in DATR/KATR).
Data-Driven Methods
Statistical techniques, including generating morphological alternations or morphological analyzers from corpora, are also applied.
Dictionary search
Unless developed and sustained by more complex models, basic dictionary search in word lists or dictionaries can link forms to linguistic descriptions but lacks generalization. It may not be feasible to have a full-form lexicon that lists every variety, particularly for languages with complex morphology.
Morphological Typology
Languages are categorized according to the way they combine morphemes and their morphological structures.
Isolating (Analytic) Languages
English has analytic tendencies, while Chinese, Vietnamese, and Thai have few words with many morphemes. Put more emphasis on auxiliary words and word order than on inflection.
Synthetic Languages
More morphemes are combined into a single word in synthetic languages.
Agglutinative languages
Morphemes in these languages like Korean, Japanese, Finnish, Tamil, and Turkish are linked cleanly one after the other (concatenative) and are tied to a single function.
Fusional Languages
Functional morphology is especially helpful for modelling morphemes that can communicate many aspects at once and fuse consequentially (nonlinearly).
Ambiguity
In languages where orthography does not completely encode phonetic form, morphological ambiguity can be substantial. The process of labelling each morpheme independently in agglutinative languages, such as Korean, is known as morphological disambiguation.
You can also Read about Lexical Categories: The Process Of Organizing Words in NLP
Morphological Productivity
The ability of morphological processes to apply to new words is known as morphological productivity.
Managing Unknown Words
Words that are absent from a basic inventory can be handled with the use of morphological processing. Unknown segment affixes and stems can be accepted by morphological parsers.