
Replication in MongoDB
Multi-platform document-oriented database MongoDB offers exceptional performance, availability, and scalability due to its replication features. Redundancy and availability are achieved by replicating data across multiple servers. It protects a database from server failures and hardware and service interruptions.
Understanding Replica Sets
MongoDB replicates via replica sets. Replica sets are mongod instances with the same dataset. The recommended replication approach for all production deployments, it provides 24/7 data availability, catastrophe recovery, read scaling, and no downtime for backups or index rebuilds.
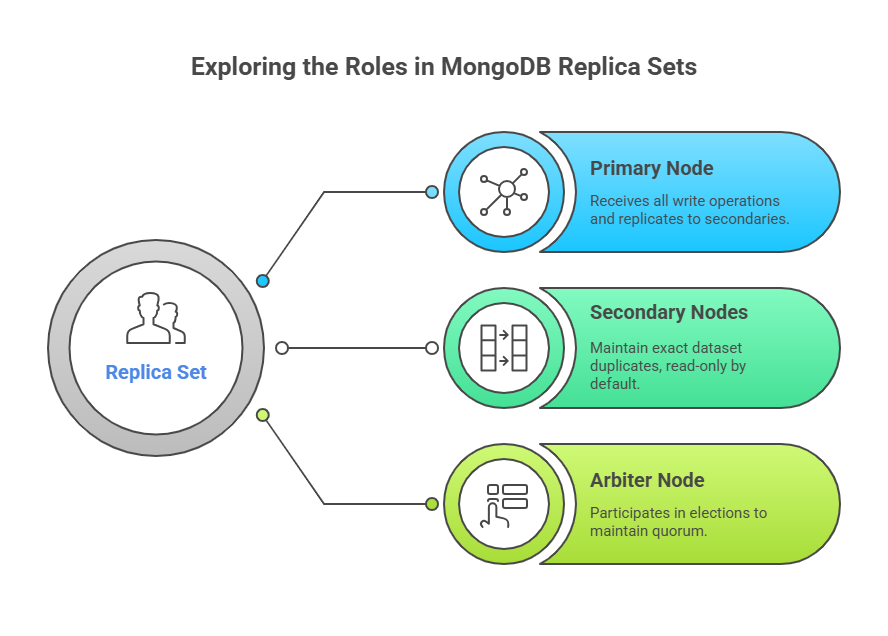
A cluster of N nodes makes up a typical replica set, and robust operation typically requires a minimum of three nodes. These nodes serve several purposes:
- Primary Node: Only one node is identified as the primary in a replica set. All write operations from client apps must be received by this node. After that, every piece of data moves from the primary to the secondary nodes.
- Secondary Nodes: The replica set’s other instances are all secondaries. They keep an exact duplicate of the dataset by applying operations from the primary. Secondary nodes are read-only by default. Clients can, however, use the mongo shell’s rs.slaveOk() to explicitly authorise reads from secondaries, albeit asynchronous replication may cause them to read somewhat stale data.
- Arbiter Node: An optional Mongod instance that does not keep a copy of the dataset is known as an arbiter node. Its only objective is to take part in elections in order to keep a quorum, which guarantees an odd number of members who can vote in order to avoid ties during primary elections.
To set up a three-node replica set on a single system, create data folders and launch mongod instances on various ports, specifying the replica set name with–replSet:
# Create data directories
mkdir /srv/mongodb/data/rs0-0
mkdir /srv/mongodb/data/rs0-1
mkdir /srv/mongodb/data/rs0-2
# Start mongod instances (in separate terminals)
mongod --port 27017 --dbpath /srv/mongodb/data/rs0-0 --replSet rs0 --smallfiles --oplogSize 128
mongod --port 27018 --dbpath /srv/mongodb/data/rs0-1 --replSet rs0 --smallfiles --oplogSize 128
mongod --port 27019 --dbpath /srv/mongodb/data/rs0-2 --replSet rs0 --smallfiles --oplogSize 128 Then, connect to one instance using the mongo shell and initiate the replica set:
mongo --port 27017
# In the mongo shell:
rs.initiate(); To add the other members to the replica set:
rs.add("<hostname>:27018");
rs.add("<hostname>:27019");The rs.conf() and rs.status() procedures allow you to examine the configuration and status of the replica set.
The Oplog (Operation Log)
The operations log, or oplog, is the central component of MongoDB’s replication. On every replicating node, the local database has the capped oplog. As a rolling record, it records all data changes.
The primary’s oplog automatically records client writes with enough information to replicate them. Secondary nodes examine the primary’s oplog for entries greater than their last applied timestamp and apply these operations asynchronously to their datasets. Proper replication requires idempotent oplog entries, which give the same effect when applied once or numerous times.
Local databases, which hold the oplog and replica set metadata like local.system.replset, are not duplicated, ensuring their locality. The –oplogSize option (value in megabytes) allows you to specify the size of the oplog at the initial run. This option determines how far a secondary can lag before a complete resync is necessary. A replica set’s resilience and latency tolerance are enhanced with a larger oplog.
Automatic Failover
High availability is achieved via replica sets’ automated failover. Replica set members monitor their health by sending heartbeats (pings) every two seconds. The remaining members identify the lack of heartbeats and choose a new primary from among the secondaries in the event that the primary node malfunctions or stops functioning (for example, because of a server outage or network partition). In most cases, the secondary with the highest priority and the most recent oplog will be elected. The former primary node returns to the replica set as a secondary node after it has recovered.
Although MongoDB strives for great durability, writes are only regarded as fully committed if they have been replicated to the majority of voting members in the replica set. Unreplicated writings may be rolled back when the previous primary returns online if a primary fails before writes are replicated to a majority. By writing operations to an on-disk journal prior to being applied to data files, journaling which is enabled by default in 64-bit MongoDB versions 2.0 and later significantly helps with crash recovery and guarantees data consistency even in the event of an unplanned shutdown.
The primary node can be stopped to mimic failover:
# In mongo shell connected to primary (e.g., port 27017)
use admin;
db.shutdownServer();After then, a new primary will be chosen by the replica set, and all incoming writes will be directed to it.
Initial Sync Processes
An initial sync process is started when a new member is introduced to a replica set or when an existing member surpasses the capacity of the primary’s oplog. This procedure guarantees that a complete and current copy of the data set is sent to the new or lagging member.
There are multiple steps involved in the initial sync:
- Cloning Databases: Each collection in each database is queried by the mongod instance, which then inserts all of the data into its own copies of the collections. At this point, _id indexes are also constructed.
- Applying Changes: The mongod modifies its dataset to account for any modifications made during the cloning process by using the oplog.
- Building Indexes: Lastly, every other index on every collection is created.
The member can enter a regular state, usually SECONDARY, after completing these processes. It may be quicker to manually copy data files from an existing member before launching a new instance of a large database rather than waiting for an initial sync to happen automatically. However, MongoDB will carry out the initial sync automatically if the data directory is empty.