
Sharding in MongoDB
MongoDB’s horizontal scaling strategy, sharding, manages data expansion, especially for huge datasets and high-throughput operations. Sharding “scales out” by dividing the dataset among several machines, or “shards,” as opposed to “scaling up” by adding more CPU and storage capabilities to a single system (vertical scaling). High performance, high availability, and simple scalability are guaranteed by this method.
Introduction to Sharding and Horizontal Scalability
A single machine might not be enough to store the data or provide a sufficient read and write throughput when the size of the data increases. Sharding solves these issues by limiting the number of processes each shard handles and the quantity of data each server needs to keep as the cluster expands. If four shards carry 256GB of a 1 terabyte dataset, each may hold less. The cluster gains horizontal capacity and throughput. MongoDB’s auto-sharding handles data splitting and rebalancing, making it transparent to applications. This lets developers focus on app development rather than scaling.
Sharding is preferred when your dataset exceeds the storage or RAM of a single MongoDB instance or when a single instance cannot handle your write operations. Due to operational complexity and overhead, sharding is usually best implemented as an unsharded deployment and converted as needed. To reduce application disruption, enable sharding before partitioning your database.
Understanding Sharded Cluster Components
In MongoDB, a sharded cluster is made up of three primary parts that cooperate:
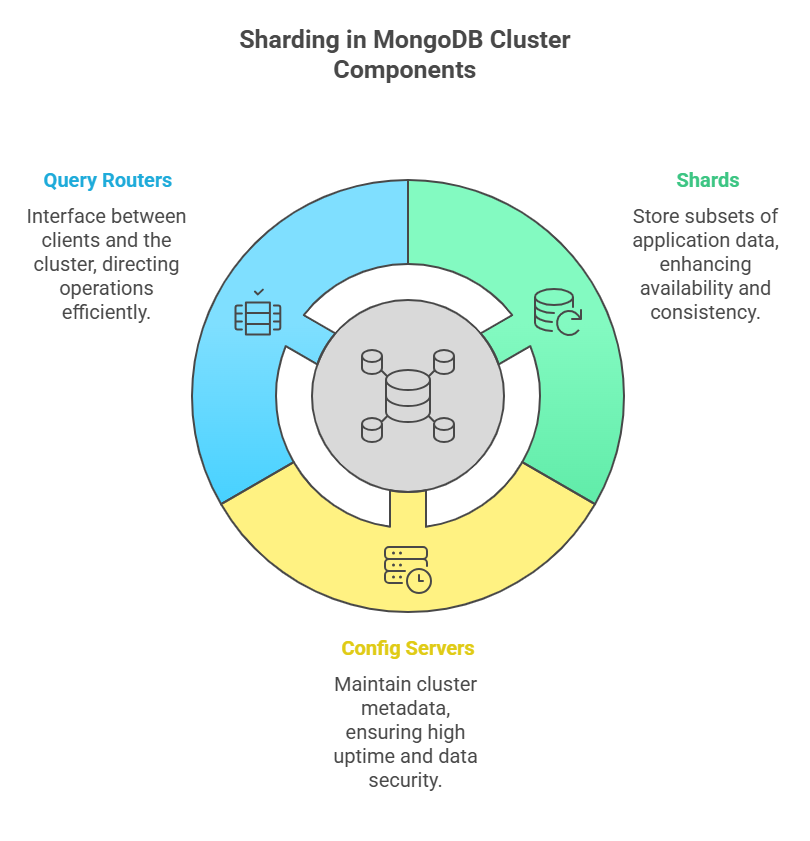
- Shards: A subset or division of the application data is stored in Shards, which are instances of MongoDB. To improve availability and data consistency, production shards are deployed as replica sets. Single mongod instances can be used as shards for development and testing, but not production. The “primary” shard holds a database’s unsharded collections.
- Config Servers: The cluster’s metadata is kept on these mongod instances. Important details like the mapping of the cluster’s dataset to the individual shards are contained in this metadata. Query routers use this metadata to direct operations to the appropriate shards. To guarantee high uptime and data security in a production setting, you need to set up precisely three configuration servers on separate servers. Certain sharding actions, such transferring pieces and launching new Mongos instances, stop working if config servers go down, although already-running Mongos instances continue to function.
- Query Routers (mongos): The interface between client apps and the sharded cluster is provided by query routers, which are instances of Mongos. They direct read and write operations to the correct shard or shards, processing them and returning results to clients. The configuration servers’ metadata is cached using mongos processes, which are lightweight and do not save persistent state. A sharded cluster can include more than one mongos instance to share the client request load. From the application’s point of view, a sharded system seems to be identical to a non-sharded one because clients connect to a Mongos instance, abstracting away the complexities of sharding.
Shard Keys and Their Importance in Data Distribution
One of the most important components of MongoDB sharding is the shard key. Every document in a sharded collection contains this type of indexed field, also known as a compound (many) indexed field. The data in the collection is split up into pieces by MongoDB using the shard key values, and these chunks are then dispersed among the shards. Because it affects how MongoDB divides data and how well Mongos instances can guide operations, the shard key selection has a big impact on performance. Insertion and query speed can be severely hampered by a poorly selected shard key.
Depending on the shard key, there are basically two kinds of sharding:
- Range-Based Sharding: This technique uses the values of the shard keys to partition the data set into ranges. Documents with “close” shard key values are likely to be in the same chunk and consequently on the same shard. Range queries work well with range-based sharding because the query router can target relevant shards. The downside is that if the shard key is monotonically increasing (such a timestamp or ObjectId), “hotspots” where all writes go to one shard can result in unequal data distribution.
- Hash-Based Sharding: This method creates chunks from field values hashed. In order to distribute write operations equitably, this guarantees a more random distribution of data among chunks and shards. Range queries on the hashed shard key are less effective because of this randomness, though, since they might have to query each shard in order to get results. MongoDB computes query hashes automatically.
When selecting a shard key, other crucial factors to take into account are:
- Cardinality: To partition data into numerous parts, MongoDB needs a shard key with many values. Keys with minimal variation can create “unsplittable chunks” that MongoDB cannot divide, even if they surpass their maximum size.
- Compound Shard Keys: Frequently, one field might not have every desirable property for a shard key. A compound shard key that combines two or more fields can be used in these situations. For instance, a username field and a _id field together can offer balanced write distribution and effective query targeting.
- Query Targeting: In order for Mongos to route queries to a particular shard or selection of shards — referred to as “targeted queries”—they must contain the shard key for best performance. It can be wasteful, particularly in bigger clusters, to broadcast queries that do not contain the shard key to every shard (also known as “scatter-gather” queries).
- Immutability: Sharding a collection locks its shard key. MongoDB versions before 4.2 could not modify a document’s shard key value after insertion; 4.2+ may, unless the field is the immutable _id.
- Indexing Requirement: Shard key fields must be indexed. For empty collections without a shard key index, shardCollection creates one automatically.
Data Distribution Mechanics
MongoDB handles data distribution automatically once sharding has been enabled on a collection and a shard key has been defined. Two background processes are involved in this:
- Splitting: A Mongos instance will automatically divide chunks into two smaller pieces once they exceed a predetermined size, by default 64 megabytes. Splits are effective metadata modifications that don’t require data migration. Insertion and update actions cause splits.
- Balancing/Migration: To guarantee that pieces are dispersed equally among the shards, a background process called the balancer runs on a Mongos instance. It transfers chunks from overloaded shards to those with fewer chunks until equilibrium is reached if it notices an imbalance (for example, one shard has noticeably more chunks than the others). For the most part, the application can see this process clearly.
Because MongoDB would otherwise take time to build and distribute chunks automatically, pre-splitting and premigrating chunks can help distribute the data equally upon import for massive data imports into an empty sharded collection.
A sharded cluster’s overall connectivity requires that clients connect to a mongos instance, which in turn needs to be able to connect to the configuration servers and the shards. Shards also need to be able to connect with the configuration servers and other shards.
// Example: Setting up a basic sharded cluster (simplified for illustration)
// This assumes mongod instances for config servers and shards are already running
// as replica sets (e.g., rs.initiate() and rs.add() for shards).
// 1. Start a mongos instance, pointing to the config servers
// On your terminal:
// mongos --configdb cfg1.example.net:27017,cfg2.example.net:27017,cfg3.example.net:27017 --port 27017 --logpath /data/mongos.log --fork
// 2. Connect to the mongos via mongo shell
// mongo --host localhost --port 27017
// 3. Add shards to the cluster (assuming 'myShardRS1' and 'myShardRS2' are replica set names)
// Replace with your actual replica set names and member addresses
sh.addShard( "myShardRS1/shard1_member1.example.net:27017,shard1_member2.example.net:27017,shard1_member3.example.net:27017" );
sh.addShard( "myShardRS2/shard2_member1.example.net:27017,shard2_member2.example.net:27017,shard2_member3.example.net:27017" );
// 4. Enable sharding for a database (e.g., 'mydatabase')
sh.enableSharding("mydatabase");
// 5. Create an index on the chosen shard key (e.g., 'username' in 'mycollection')
// If the collection is not empty, this step is mandatory before sharding the collection.
use mydatabase;
db.mycollection.createIndex({"username": 1});
// 6. Shard the collection using the defined shard key
sh.shardCollection("mydatabase.mycollection", {"username": 1});
// 7. Check the sharding status
sh.status();